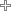


In order to display meaningful results against your search queries, Google Search Engine uses what is known as a web crawler or ‘spider’ to scour and mine the web for data. Google’s ‘spider’, called Googlebot, retrieves this unimaginably large magnitude of data and hands it over for indexing and processing. As soon as any search is made, algorithms begin their work and, based on the many heuristic clues and signals defined, data is pulled out from the index and the results ranked.

So we have the Googlebot that crawls the web, the indexer that indexes the retrieved data – estimated to be over 100 million gigabytes! – and the query processor, which takes the user query and compares it to the indexed data to give you search results.
The Crawl
Googlebot has a defined yet always evolving list of web URLs it is instructed to visit. This list changes with each crawl, and also relies on Sitemap data generated by webmasters to grow. When the bot hits a URL, it detects further associated links (SRC and HREF) to add to its list of pages to crawl. This drilldown into each ‘domain’ is known as deepcrawling. Googlebot usually hits your webpage every few seconds, adjusting its crawl frequency according to parameters like frequency of content updates.
As a webmaster, you also help define how Googlebot goes about making sense of your website and indexing it. An XML Sitemap helps a lot. While Googlebot can often retrieve a majority of the content on a website, a sitemap organizes the structure hollistically, allowing the bot to crawl it in a more orderly, intelligent manner. This holds especially true for large sites, new sites, and sites where all the content is not necessarily interlinked in a structured manner.
You also get to choose which pages you want Googlebot to actually submit for indexing. If you have certain URLs on your domain you don’t want Google to display on search results, you can edit your website’s robots.txt to add the rel=”nofollow” attribute to those links.
That in a nutshell is how Google uses Googlebot to crawl the World Wide Web. Remember, things like duplicate content and broken links not only penalize your website’s rankings, but also reduce the time Googlebot spends finding actual, worthy content on your website. This is because Googlebot’s time on your site is budgeted, it doesn't just linger around till it understands every aspect. It is the duty of the website developer and the SEO to ensure that the site is structured to make it as easy as possible for Googlebot to read and submit its findings.
If you’d like to find out how many broken links and pages of duplicate content you have, and whether your sitemap and robots.txt is in order, do get in touch http://gdata.in/contact-us with us for a complimentary SEO Audit of your website.



